1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
import requests
from lxml import html
import time
import hashlib
normal_headers = {
r"User-Agent": r"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
r"Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.56 "
}
VPN1_headers = {
r"Accept": r'*/*',
r"Accept-Encoding": r"gzip, deflate, br",
r"Content-Type": r"application/x-www-form-urlencoded; charset=UTF-8",
r"User-Agent": r"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
r"Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.56 ",
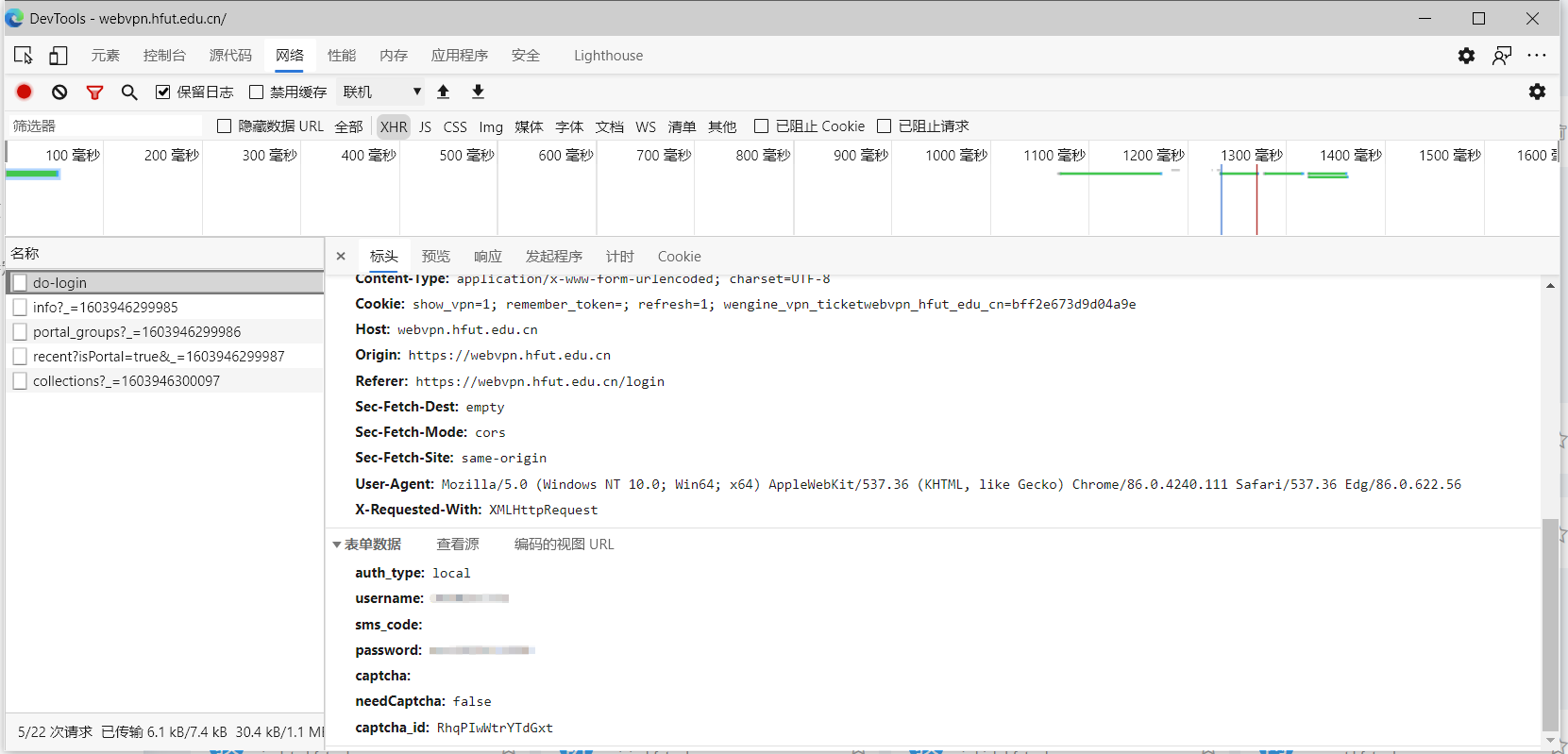
r"Cookie": r"show_vpn=1; wengine_vpn_ticketwebvpn_hfut_edu_cn=783a9268eeff4127; remember_token=",
r"Host": r"webvpn.hfut.edu.cn",
r"Origin": r"https://webvpn.hfut.edu.cn",
r"Referer": r"https://webvpn.hfut.edu.cn/login",
r"Sec-Fetch-Dest": r"empty",
r"Sec-Fetch-Mode": r"cors",
r"Sec-Fetch-Site": r"same-origin",
r"X-Requested-With": r"XMLHttpRequest"
}
VPN2_headers = {
r"Accept": r"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,"
r"application/signed-exchange;v=b3;q=0.9",
r"Accept-Encoding": r"gzip, deflate, br",
r"User-Agent": r"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
r"Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.56 ",
r"Cookie": r"show_vpn=1; wengine_vpn_ticketwebvpn_hfut_edu_cn=783a9268eeff4127; remember_token=",
r"Host": r"webvpn.hfut.edu.cn",
r"Referer": r"https://webvpn.hfut.edu.cn/login",
r"Sec-Fetch-Dest": r"document",
r"Sec-Fetch-Mode": r"navigate",
r"Sec-Fetch-Site": r"same-origin",
r"Sec-Fetch-User": r"?1",
r"Upgrade-Insecure-Requests": "1"
}
VPN3_headers = {
r"Accept": r'application/json, text/javascript, */*; q=0.01',
r"Accept-Encoding": r"gzip, deflate, br",
r"User-Agent": r"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
r"Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.56 ",
r"Cookie": r"show_vpn=1; wengine_vpn_ticketwebvpn_hfut_edu_cn=783a9268eeff4127; remember_token=",
r"Host": r"webvpn.hfut.edu.cn",
r"Referer": r"https://webvpn.hfut.edu.cn/",
r"Sec-Fetch-Dest": r"empty",
r"Sec-Fetch-Mode": r"cors",
r"Sec-Fetch-Site": r"same-origin",
r"X-Requested-With": r"XMLHttpRequest"
}
VPN_url = r'https://webvpn.hfut.edu.cn/'
def get_captcha_id(page):
xpath = r'//*[@id="captcha-wrap"]/div/div/input/@value'
page.encoding = page.apparent_encoding
selector = html.fromstring(page.text)
return selector.xpath(xpath)[0]
VPN_session = requests.Session()
data = {
r'auth_type': r'local',
r'username': r'填用户名',
r'sms_code': r'',
r'password': r'填密码',
r'captcha': r'',
r'needCaptcha': r'false',
r'captcha_id': get_captcha_id(VPN_session.get(r'https://webvpn.hfut.edu.cn/login', headers=normal_headers))
}
res0 = VPN_session.post(VPN_url + r'do-login', headers=VPN1_headers, data=data)
res1 = VPN_session.get(VPN_url, headers=VPN2_headers)
res2 = VPN_session.get(VPN_url + r'user/info?_=' + str(int(time.time() * 1000)), headers=VPN3_headers)
print(res1)
|